Si tienes que importar a Power BI archivos CSV que estén en un data lake, Azure Synapse es una opción muy interesante, y aunque no lo creas, no es costosa.
En esta entrada te explico paso a paso todo el proceso, que consiste en vincular el data lake con Synapse, crear en Synapse una vista SQL que acceda a los datos de los archivos CSV y en Power BI conectarse a Synapse y configurar la actualización incremental. También hablo de los costes y en cada paso hago recomendaciones para mantener los costes bajo control.
Si tienes acceso a una subscripción de Azure y quieres ir siguiendo los pasos, puedes descargar los archivos CSV desde GitHub y subirlos a un Azure Data Lake.
Archivos CSV en el data lake
Los archivos CSV con los que vamos a trabajar contienen los datos del registro de ventas de una tienda y tienen las siguientes columnas:
- Fecha
- Codigo Cliente
- Codigo Vendedor
- Codigo Producto
- Precio Unitario
- Cantidad
El separador de columnas es la coma, y la primera fila de cada archivo tiene los nombres de las columnas.
Estos archivos están almacenados en un Azure Data Lake, o sea, en una cuenta de almacenamiento que tiene habilitado el esquema de nombre jerárquico, y están dentro de un contenedor con el nombre ventas. Se ha creado una jerarquía de carpetas para el año, el mes y el día y los archvios CSV se han ubicado dentro de la carpeta del día que le correspende.

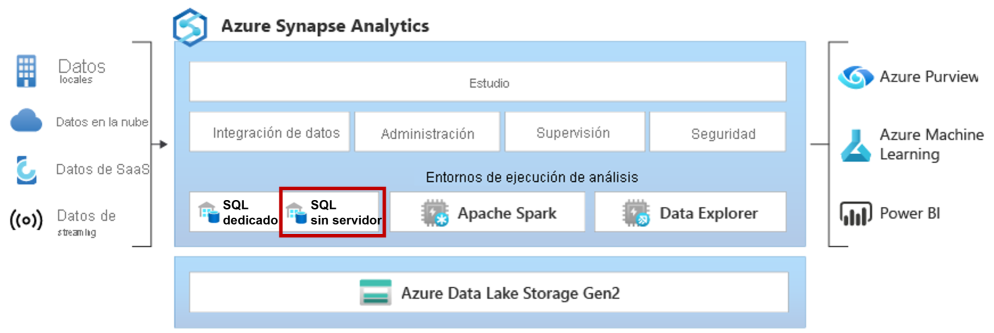
Azure Synapse
El servicio Azure Synapse Analytics está formado por varias componentes con los que podemos ingerir, explorar, preparar, transformar, administrar y servir datos de una manera unificada.
Para consumir los archivos CSV, usaremos el grupo de SQL sin servidor, con el cual podemos hacer consultas SQL directamente sobre archivos que estén almacenados en un Azure Date Lake.
Para comenzar a trabajar con Synapse, debemos crear un área de trabajo de Synapse, lo cuál se puede hacer desde el portal de Azure, creando un nuevo recurso de Azure Synapse Analytics.
Hay que tener en cuenta que el área de trabajo necesita un data lake para usarlo como su sistema de archivos, por lo que al crear el recurso debemos indicar una cuenta de almacenamiento que ya exista, o bien que queremos crear una cuenta nueva.
Una vez creado el recurso, entramos al área de trabajo y abrimos Synapse Studio para acceder a los servicios de Synapse.

Ya dentro de Synapse Studio, para poder acceder a los archivos CSV vamos a establecer un vínculo con la cuenta de almacenamiento donde está el data lake que contiene dichos archivos.
Quiero aclarar que en este caso los archivos CSV están en una cuenta de almacenamiento distinta a la que se indicó cuando creamos el área de trabajo de Synapse. De hecho, podriamos vincular con Synapse una cuenta de almacenamiento que pertenezca a otra susbcripción de Azure.
Te recuerdo que la cuenta de almacenamiento tiene que tener habilitado el espacio de nombre jerárquico, para que funcione como un data lake.
Una recomendación importante es que la cuenta de almacenamiento esté en la misma región de Azure en la que está el área de trabajo de Synapse.

Después de establecer el vínculo con el data lake, vamos a hacer una consulta SQL desde el grupo SQL sin servidor, para comprobar que todo está bien. No temas, que no vamos a incurrir en ningún coste.
Con Synapse Studio podemos crear la consulta SQL en unos simples pasos. Primero vamos a la página Datos y hacemos clic en Vinculado para ver una lista de los servicios que están vinculados. Buscamos el data lake que vinculamos anteriormente y navegamos por sus contenedores y sus carpetas. Seleccionamos el contenedor ventas y nos movemos por la carpeta del año, luego la de un mes y finalmente la de un día, hasta que veamos un archivo CSV. Parados sobre el archivo, usamos el botón derecho del ratón y seleccionamos la opción Nuevo script SQL y luego Seleccionar las primeras 100 filas.
Esto nos llevará al editor de SQL donde veremos la consulta creada. La podemos ejecutar con el botón Ejecutar que está arriba a la izquierda, o con la tecla F5. Adelante, no temaís, no vamos a gastar nada todavía. Si todo salió bien debemos ver parte del contenido del archivo CSV que seleccionamos.

Si miramos en la parte superior y central del editor de SQL podemos ver que dice Conectarse a Integrado, lo que indica que estamos conectados al grupo SQL sin servidor, el cual no hay que iniciar, ni se puede parar, porque Synapse se encarga de hacerlo por nosotros y de gestionar la capacidad necesaria cuando hacemos una consulta SQL. Al lado podemos ver que en este momento estamos conectados a la base de datos master. En un rato, antes de crear la vista SQL, vamos a crear una nueva base de datos.
Más adelante explicaré los detalles de esta consulta SQL, que nos servirá como base para crear la vista. Por ahora lo importante es copiar el punto de acceso para el data lake y que podemos ver dentro de la consulta, en la línea que contiene la palabra BULK y que tiene el formato https://xxxx.dfs.core.windows.net/ventas donde xxxx se sustituirá por el nombre de la cuenta de almacenamiento, y ventas es el nombre del contenedor.
Ya estamos listos para crear la vista, pero antes hablaré de los costes.
Coste del grupo SQL sin servidor de Synapse
En el grupo SQL sin servidor sólo se paga por el volumen de datos utilizados para procesar las consultas SQL. Al momento de escribir este blog, el coste en la región Oeste de Europa es de €4,756 por TB de datos. Para calcular el coste siempre se redondea al siguiente MB y cada consulta tiene un cargo mínimo de 10 MB.
Las instrucciones SQL de DDL, como CREATE, ALTER o DROP no tienen coste.
Se mide tanto la cantidad de datos que se cargan en el motor de SQL sin servidor para poder completar la consulta, como los datos que son enviados con los resultados de la consulta. En el caso de CSV hay que leer un archivo completo para procesar cualquier consulta. Por ejemplo, una consulta que cuente la cantidad de filas de un archivo SELECT COUNT(*) FROM .... lee todo el archivo CSV, pero luego el volumen del resultado es muy pequeño. Mientras que una consulta que devuelva todas las filas y todas las columnas SELECT * FROM ... costará un poco más porque igual leerá todo el archivo CSV y además el volumen del resultado es todo el archivo CSV.
¿Y cuanto ha costado la consulta que hemos ejecutado antes? El tamaño del archivo CSV es de 333 KB, pero recuerda que el coste mínimo es 10 MB, si asumimos que 1 TB equivale a 1 millón de MB, podemos calcular €4,756 * 10 / 1.000.000 = €0,0004756. ¿Qué te dije? Podemos decir que no hemos gastado nada.
Con Synapse Studio podemos ver un registro de las consultas que se han hecho en el grupo SQL sin servidor y el volumen de datos procesado. Para ello vamos a la página Monitor y entramos a las Solicitudes de SQL. En la imagen se puede ver cómo se han ejecutado dos consultas y que en cada una se procesaron 10 MB.

Creando la vista SQL
Vamos a crear la vista SQL que luego usaremos desde Power BI.
Primero creamos una nueva base de datos en el grupo SQL sin servidor, que lo podemos hacer visualmente o con la instrucción SQL CREATE DATABASE.
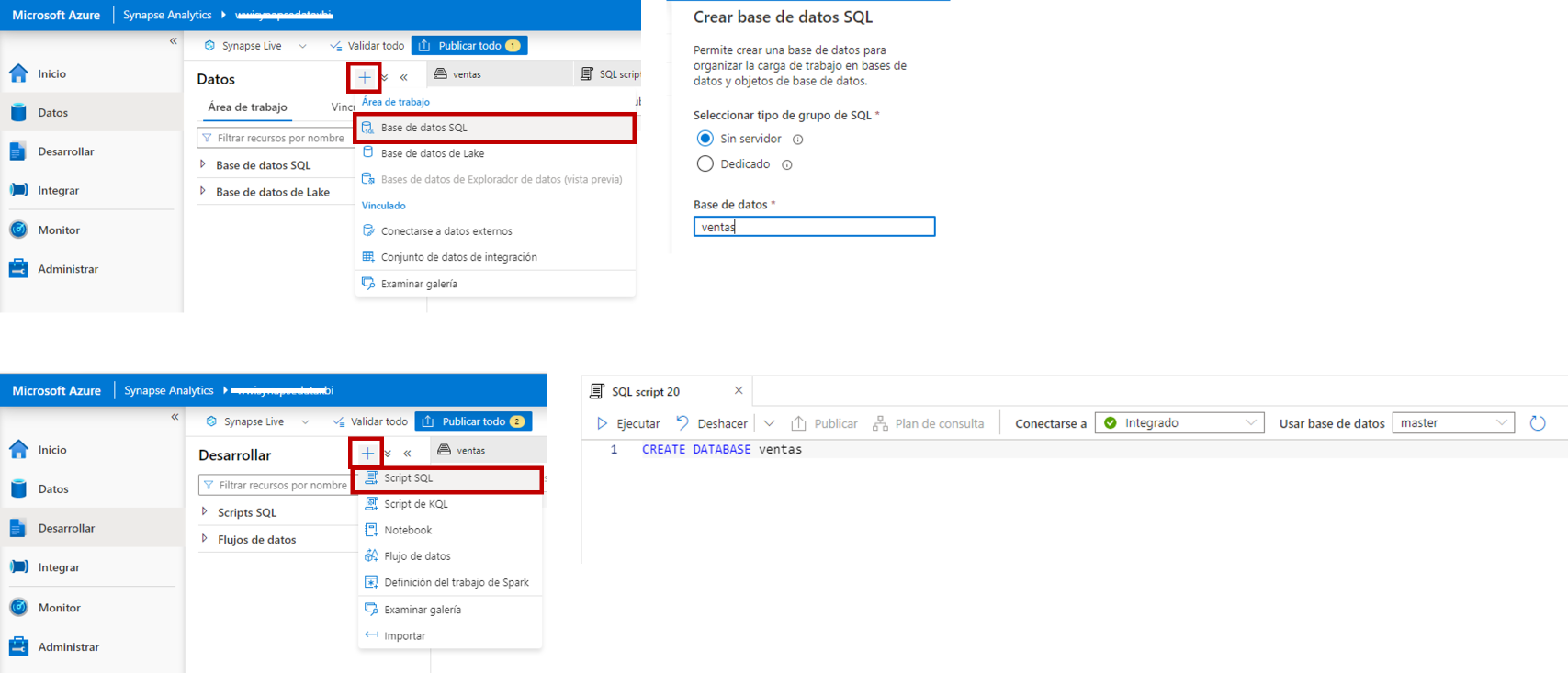
Para crear la base de datos visualmente, vamos a la página Datos, hacemos clic en el botón + y escogemos la opción Base de datos SQL y en el formulario que se abre indicamos que es en el grupo SQL sin servidor y escribimos el nombre de la base de datos: ventas.
Para crear la base de datos con SQL, vamos a la página Desarrollar, hacemos clic en el botón + y escogemos la opción Script SQL, lo que abrirá un nuevo editor de SQL, donde escribimos la instrucción CREARE DATABASE ventas y la ejecutamos con la tecla F5 o con el botón Ejecutar.
Como segundo paso, crearemos un origen de datos externo utilizando el punto de conexión al data lake: https://xxxx.dfs.core.windows.net/ventas (recuerda que xxxx hay que sustituirlo por el nombre de la cuenta de almacenamiento de Azure y que ventas es el nombre del contenedor donde están los archivos CSV). Para ello utilizaremos las siguientes instrucciones de SQL:
USE ventas;
CREATE EXTERNAL DATA SOURCE VentasDS
WITH (
LOCATION = 'https://xxxx.dfs.core.windows.net/ventas'
)
La instrucción USE es para cambiarnos de la base de datos master a la base de datos ventas que creamos en el paso anterior.
Para ejecutar estas instrucciones SQL en Synapse Studio, vamos a la página Desarrollar, hacemos clic en el botón + y escogemos la opción Script SQL, para abrir un editor de SQL. O si en el paso anterior creaste la base de datos con SQL, puedes usar ese mismo editor que ya está abierto. Recuerda usar la tecla F5 o el botón Ejecutar.
¡Ya estamos listos para crear la vista! Primero mostraré la instrucción SQL, después mostraré el resultado de ejecutar una consulta SQL que utilice esta vista y más tarde explicaré las distintas partes de la instrucción SQL.
Esta es la instrucción SQL para crear la vista:
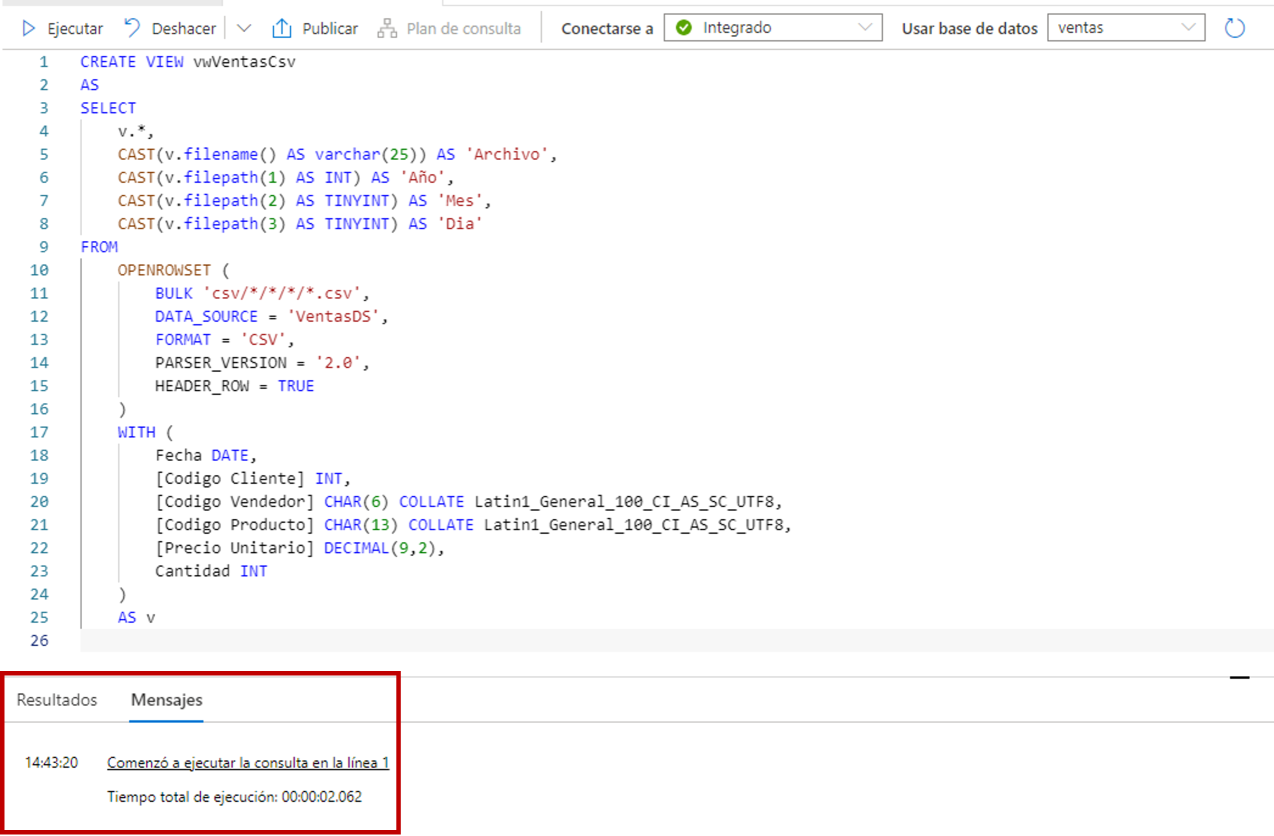
CREATE VIEW vwVentasCsv
AS
SELECT
v.*,
CAST(v.filename() AS varchar(25)) AS 'Archivo',
CAST(v.filepath(1) AS INT) AS 'Año',
CAST(v.filepath(2) AS TINYINT) AS 'Mes',
CAST(v.filepath(3) AS TINYINT) AS 'Dia'
FROM
OPENROWSET (
BULK 'csv/*/*/*/*.csv',
DATA_SOURCE = 'VentasDS',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE
)
WITH (
Fecha DATE,
[Codigo Cliente] INT,
[Codigo Vendedor] CHAR(6) COLLATE Latin1_General_100_CI_AS_SC_UTF8,
[Codigo Producto] CHAR(13) COLLATE Latin1_General_100_CI_AS_SC_UTF8,
[Precio Unitario] DECIMAL(9,2),
Cantidad INT
)
AS v
La puedes ejecutar en el editor SQL que ya tienes abierto. Si no tienes ningún editor SQL abierto, cuando abras uno nuevo recuerda cambiar a la base de datos ventas. Al ejecutar esta instrucción no verás ningún resultado, pero puedes cambiarte al panel de mensajes para saber que la consulta se ejecutó con éxito.
Ahora que hemos creado la vista, vamos a utilizarla en una consulta SQL para ver las columnas que devuelve. Ejecutamos la consulta SELECT TOP 100 * FROM vwVentasCsv y observamos el resultado.
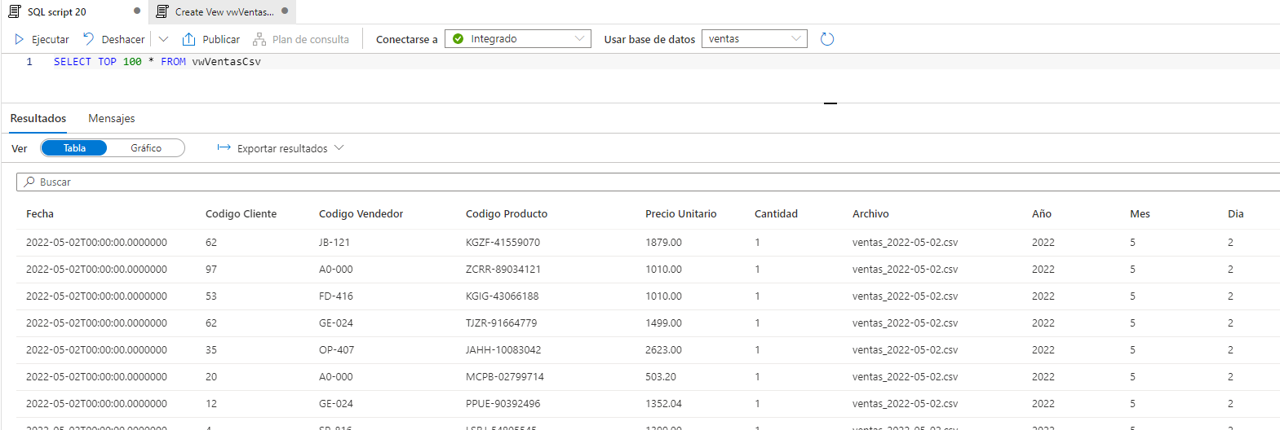
Las primeras columnas del resultado coinciden con las columnas de los archivos CSV. A continuación tenemos una columna con el nombre del archivo CSV y luego hay 3 columnas con el año, el mes y el día.
Para explicar cómo se obtiene este resultado voy a analizar la vista por partes y comienzo con OPENROWSET.
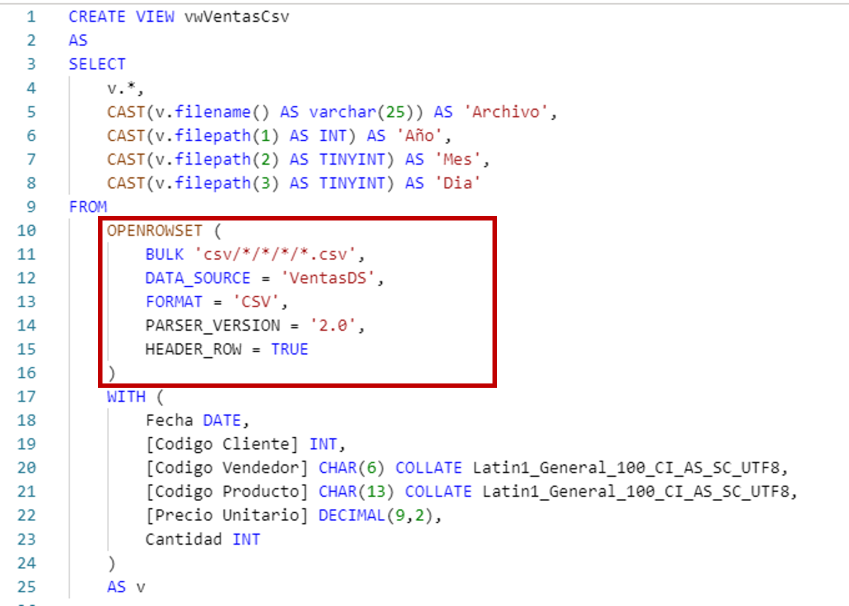
Con OPENROWSET se indica el origen y el formato de los archivos.
En la línea 12 DATA_SOURCE = 'VentasDS' se hace referencia al origen de datos externo que creamos antes y que apunta al data lake y al contenedor ventas.
En la línea 11 BULK 'csv/*/*/*/*.csv' el * se utiliza como comodín para indicar que dentro del contenedor ventas se revisen las carpetas que están debajo de la carpeta csv y que correspenden a un primer nivel con el año, un segundo nivel con el mes y un tercer nivel con el día, y ya dentro de la carpeta del día, a todos los archvios con cualquier nombre y con la extensión csv.
Pues como se ve, con esta vista podemos extraer datos de varios archivos, todos los que estén en la estructura de carpetas indicada, y no de un sólo archivo como era el caso de la primera consulta que hicimos. Esto nos da un gran poder y al mismo tiempo una gran responsabilidad porque si no somos cuidadosos podemos disparar los costes.
La línea 13 FORMAT = 'CSV' está clara, sólo añadir que los otros formatos admitidos son PARQUET y DELTA.
La línea 14 PARSER_VERSION = '2.0' es específica para CSV y se recomienda utilizar la versión 2.0 del motor que procesa los CSV porque es más eficiente. Sólo se debe utilizar la versión 1.0 si tenemos archivos CSV con alguna característica que no esté soportada por la versión 2.0. Si no indicamos nada, se utilizará la versión 1.0.
En la línea 15 HEADER_ROW = TRUE se indica que los archivos CSV tienen una primera fila con los nombres de las columnas.
OPENROWSET tiene otros parámetros para indicar los separadores, etc., pero con los valores por defecto es suficiente para que entienda la estructura de los CSV que estamos utilizando, donde el separador es la coma.
El próximo bloque que explicaré es el WITH que viene a continuación del OPENROWSET.
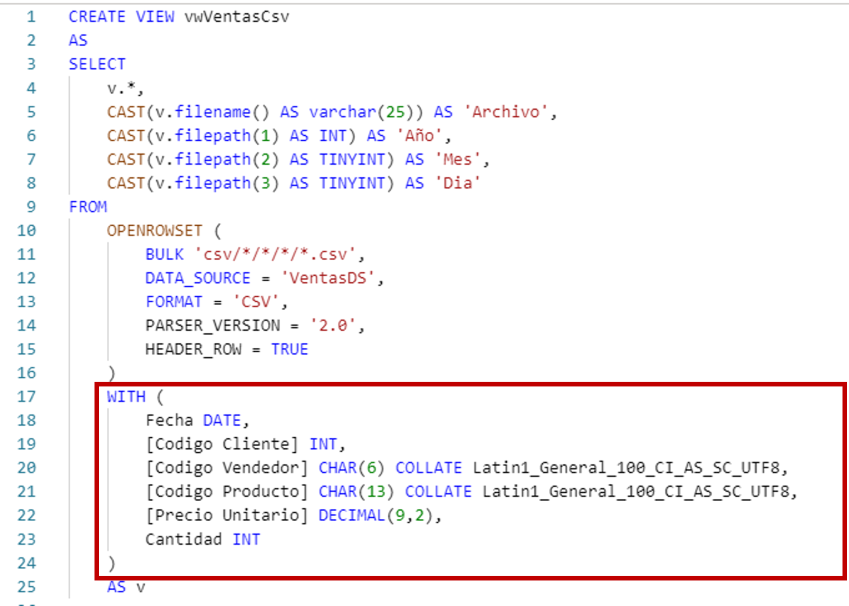
Con la instrucción WITH se indican los nombres y los tipos de datos de las columnas. No es obligatoria y si se omite, los tipos de datos se infieren analizando las 100 primeras filas.
Pero se recomienda utilizarla siempre porque así podemos indicar explícitamente los tipos de datos, lo que nos permite utilizar el tipo de dato más pequeño posible.
Si miramos en la línea 20, la columna Codigo Vendedor es de tipo CHAR(6) porque estamos seguros de que todos los códigos tienen ese tamaño. Además se ha utilizado la instrucción COLLATE porque los archivos CSV están codificados con UTF-8. De no indicar el COLLATE, la consulta daría un error. Con la columna Codigo Producto sucede algo similar.
Finalizo el análisis de la vista con el bloque SELECT.

La instrucción SELECT define las columnas que formarán el resultado.
La línea 4 v.* devuelve todas las columnas que se han indicado en el bloque WITH y que son todas las columnas de los archivos CSV.
En la línea 5 se utiliza la función filename() que retorna el nombre del archivo de donde provienen los datos de cada fila. Recuerda que con esta vista podemos devolver datos de varios archivos CSV. El texto retornado por la función es de tipo nvarchar(1024) pero los nombres de nuestros archivos no son tan grandes, por lo que siguiendo las recomendaciones lo convertimos a un tipo de datos más pequeño: varchar(25).
En las líneas 6, 7 y 8 se utiliza la función SQL filepath() con los argumentos 1, 2 y 3 respectivamente. Para entender cómo funciona hay que mirar de nuevo dentro del bloque OPENROWSET, en la línea 11 BULK 'csv/*/*/*/*.csv'.
filepath(1)se refiere alprimer asterisco (*)de la rutacsv/*/*/*/*.csv, que sería la carpeta delaño, por ejemplo 2022filepath(2)se refiere alsegundo asterisco (*)de la rutacsv/*/*/*/*.csv, que sería la carpeta delmes, por ejemplo 06filepath(3)se refiere altercer asterisco (*)de la rutacsv/*/*/*/*.csv, que sería la carpeta deldía, por ejemplo 01
El resultado de esta función también es de tipo nvarchar(1024) y en este caso lo convertivos a números enteros.
Las funciones filaneme() y filepath() son muy interesantes porque cuando se usan en el SELECT, como hemos visto, nos devuelven un resultado, pero además se pueden usar para filtrar, o sea en una instrucción WHERE, y en ese caso sólo se procesan los archivos que estén en la ruta filtrada, por lo que se reduce el coste.
Lo que he afirmado antes es muy importante, por lo que lo voy a repetir y en negritas. Utilizando las funciones filepath() y filename() y particionando de una manera apropiada las carpetas, podemos reducir los costes de las consultas que hacemos con el grupo SQL sin servidor de Synapse. A esto se le conoce como poda de partición (partition pruning).
Vamos a verlo en la práctica con dos consultas SQL que cuentan el total de ventas para un día, lo que en un caso filtraremos por la columna Fecha y en el otro caso filtraremos por las columnas Año, Mes y Día.
Estas son las consultas:
SELECT COUNT(*) FROM vwVentasCsv WHERE Fecha = '2022-06-01'
SELECT COUNT(*) FROM vwVentasCsv WHERE [Año] = 2022 AND Mes = 6 AND Dia = 1
Ambas consultas darán el mismo resultado, pero la primera costará más porque procesará todos los archivos, mientras que la segunda sólo procesará el archivo de un día.
Como se puede observar en la imagen siguiente, la primera consulta procesó 25 MB de datos, mientras que la segunda, que si utiliza la poda de partición, procesó el mínimo de 10 MB.

Bueno, ya lo tenemos todo listo del lado de Synapse por lo que podemos pasar a Power BI.
Power BI
Vamos a conectarnos desde Power BI Desktop a la vista que hemos creado en el grupo SQL sin servidor de Synapse. Y lo haremos usando el conector de base de datos SQL Server, aunque en la interfaz gráfica de Power Query tenemos varios opciones, pero todas utilizan dicho conector.
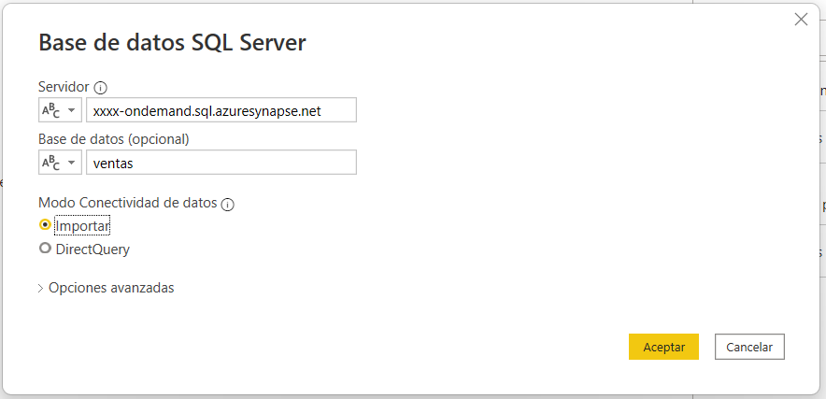
Antes de comenzar a trabajar en Power BI Desktop, regresamos al portal de Azure para ir al área de trabajo de Synapse y copiar la cadena de conexión que vamos a utilizar. Hay que buscar en Información general, donde dice Punto de conexión de SQL sin servidor (hay que mirar el tooltip para leer todo el texto). Tiene este formato xxxx-ondemand.sql.azuresynapse.net, donde xxxx se cambia por el nombre del área de trabajo de Synapse.

¡Ahora si! Entramos en Power BI Desktop donde podemos usar uno de estos conectores:
- Azure Synapse Analytics SQL
- Azure SQL Database
- Base de datos SQL Server
Al conectarnos con cualquiera de estas opciones, nos aparecerá el mismo formulario del conector de base de datos SQL Server, donde completaremos el nombre del servidor con el punto de conexión que copiamos antes y en el nombre de la base de datos escribiremos ventas.
Antes de continuar quiero hacer dos comentarios.
Primero, hay otro conector con el nombre Área de trabajo de Azure Synapse Analytics, que está en beta, y que nos facilitaría la conexión porque no tendriamos que buscar previamente la dirección al punto de conexión. Pero este conector no funciona aún con el grupo SQL sin servidor.
Segundo, no es recomendable usar DirectQuery con el grupo SQL sin servidor por dos razones: rendimiento y costes.
Continuando con el proceso de conexión, ahora debemos entrar las credenciales, donde podemos usar las mismas credenciales con las que accedimos al portal de Azure. También es posible crear usuarios en la base de datos y utilizar esas credenciales.
Lo siguiente es seleccionar la vista vwVentasCsv que es el único objeto que hemos creado en la base de datos ventas. Y usamos el botón Transformar datos para entrar al editor de Power Query.
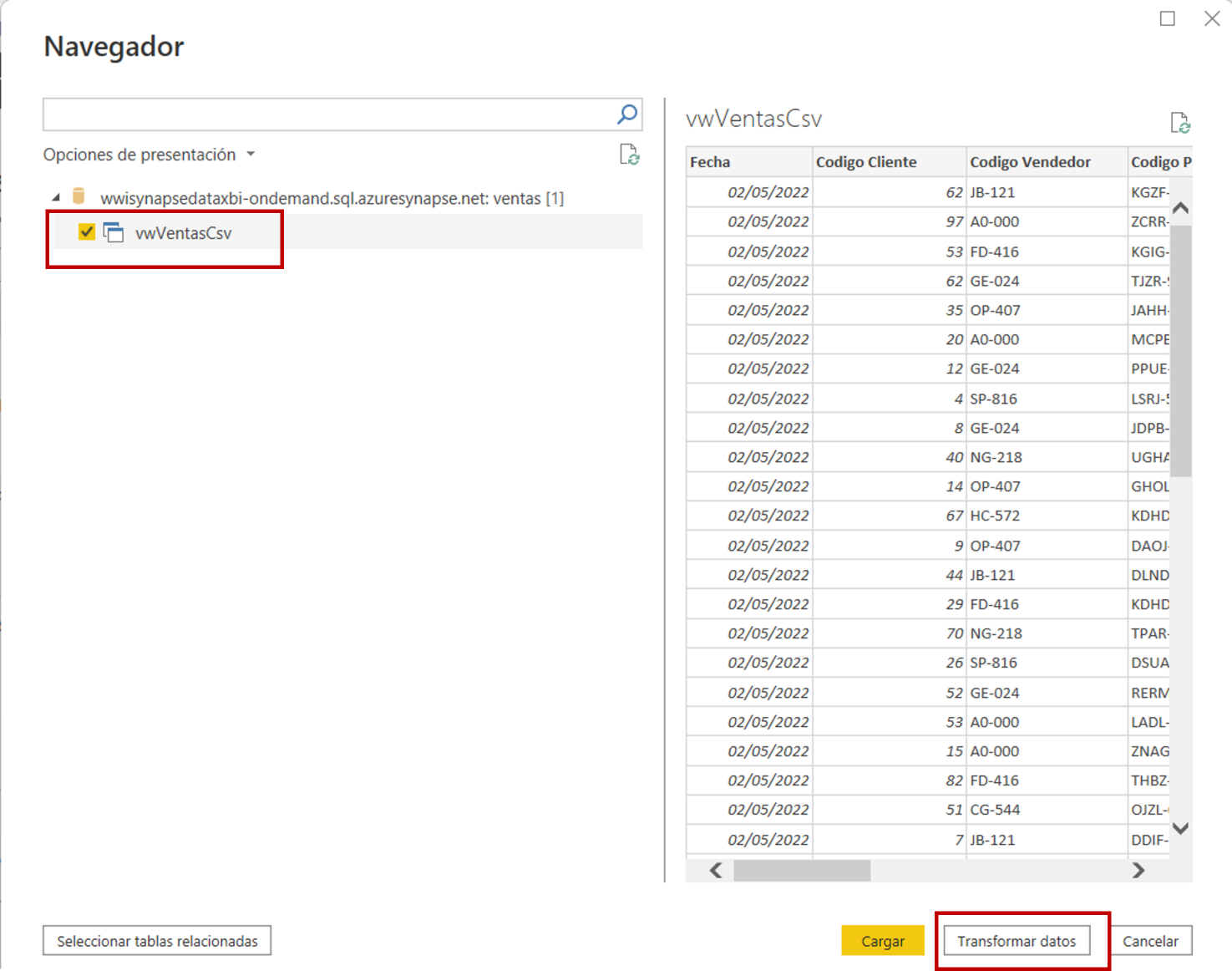
Bueno, ya estamos conectados a los archivos CSV que están en el data lake!
Pero recuerda que Synapse nos está cobrando por cada consulta que hagamos, por lo que tenemos que ser cuidadosos mientras estemos trabjando en el editor de Power Query. Una manera de hacerlo es filtrar las filas con las columnas Año, Mes y Dia para que las consultas sólo usen un archivo CSV, en lugar de todos los archivos de todas las carpetas.
De hecho, cuando usemos el grupo SQL sin servidor de Synapse desde Power BI es muy recomendable configurar la actualización incremental, porque así el grueso del coste estará en la primera carga, y en las cargas incrementales sólo se procesarán los archivos nuevos.
Y es lo que vamos a hacer para terminar, configurar la actualización incremental utilizando las columnas Año, Mes y Dia que son las que nos garantizan la poda de partición.
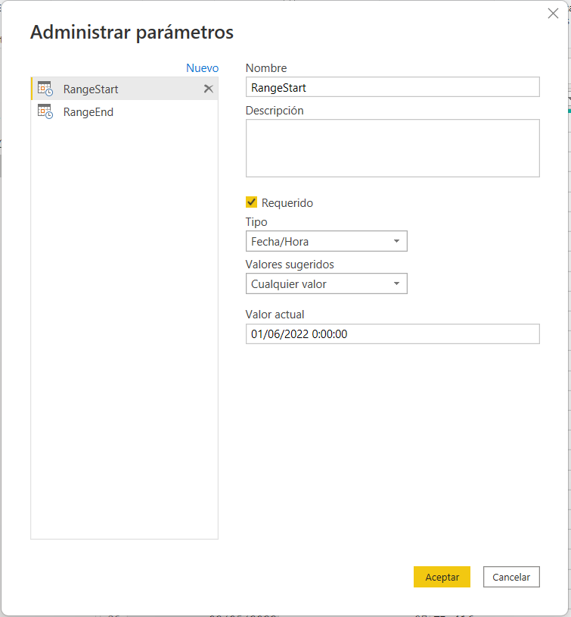
Lo primero es crear los parámetros de consulta RangeStart y RangeEnd, de tipo fecha/hora y con los valores 2022-06-01 y 2022-06-02 para que mientras estemos trabajando localmente con Power BI Desktop nos filtre un sólo día.
A continuación utilizaremos los parámetros de consulta para filtrar las filas, usando las columnas Año, Mes y Dia, y lo vamos a hacer en dos pasos donde vamos a utilizar código Power Query M.
El primer paso consiste en agregar una columna personalizada con el nombre FechaNumero y con esta fórmula: [Año] * 10000 + [Mes] * 100 + [Dia] con lo que obtendremos un valor numérico como este: 20220601.

En un segundo paso filtramos la nueva columna FechaNumero con los parámetros RangeStart y RangeEnd. Empezamos por crear el filtro con la interfaz gráfica de Power Query donde filtramos con unos valores fijos, y luego modificamos la fórmula para sustituir los valores fijos por expresiones Power Query M que usen los parámetros RangeStart y RangeEnd.

Como se puede ver en la imagen, se ha aplicado un filtro mayor o igual que y otro menor que. Es importante hacerlo de esta manera para que funcione bien la actualización incremental.
Si miramos el código Power Query M de este paso en la barra de fórmula, luce así:
= Table.SelectRows(#"Personalizada agregada", each [FechaNumero] >= 20220601 and [FechaNumero] < 20220602)
Vamos a sustituirlo por este otro código, que utiliza los parámetros RangeStart y RangeEnd.
= Table.SelectRows(#"Personalizada agregada", each [FechaNumero] >= Date.Year(RangeStart) * 10000 + Date.Month(RangeStart) * 100 + Date.Day(RangeStart) and [FechaNumero] < Date.Year(RangeEnd) * 10000 + Date.Month(RangeEnd) * 100 + Date.Day(RangeEnd))
Si todo salió bien, debemos ver que los datos están filtrados para un solo día.
Es importante comprobar que no se haya roto el plegado de consulta, para así garantizar que el filtro que hemos aplicado llegue como una consulta nativa a Synapse y este sólo procese los archivos necesarios.

Luego de aplicar este filtro podemos quitar las columnas Año, Mes, Dia, FechaNumero y Archivo, si no las necesitamos más.
Para completar la configuración de la actualización incremental, tenemos que aplicar los cambios para cargar la tabla en el modelo, y desde la pantalla de modelado usamos el clic derecho del ratón en el encabezado de la tabla y escogemos la opción Actualización incremental.

Ya lo que queda es publicar en el servicio de Power BI. Te recomiendo que después de publicar, compruebes en Synapse que en las actualizaciones incrementales sólo se están procesando los archivos nuevos.