En esta entrada queremos proponer una arquitectura donde se utilicen dos áreas de trabajo, una con capacidad Fabric para realizar la ETL de los datos y otra área de trabajo con licencia PRO que contiene el modelo semántico en modo de almacenamiento importar. La idea es mejorar el proceso de ETL que tenemos sustituyendo los flujos de datos GEN 1 por los componentes de ingeniería de datos de Fabric: flujos de datos GEN 2, las canalizaciones y los cuadernos de notas de Spark, apagando y encendiendo la capacidad Fabric para mantener bajos los costes.
Arquitectura actual
Tenemos un cliente para el cuál hemos desarrollado un modelo semántico cuyos orígenes de datos provienen de distintas fuentes: SharePoint, MySQL y API REST. Conectado a ese modelo semántico tenemos un informe que está publicado en el servicio de Power BI en un área con licencia PRO. El número de visores del informe está sobre las 30 personas y todos tienen licencia de Power BI Pro, lo que supone un coste de alrededor de 330 € mensuales aproximadamente. El cliente no desea comprar una capacidad Premium para el área que contiene el informe y en la siguiente imagen puedes ver la arquitectura actual con que cuenta:
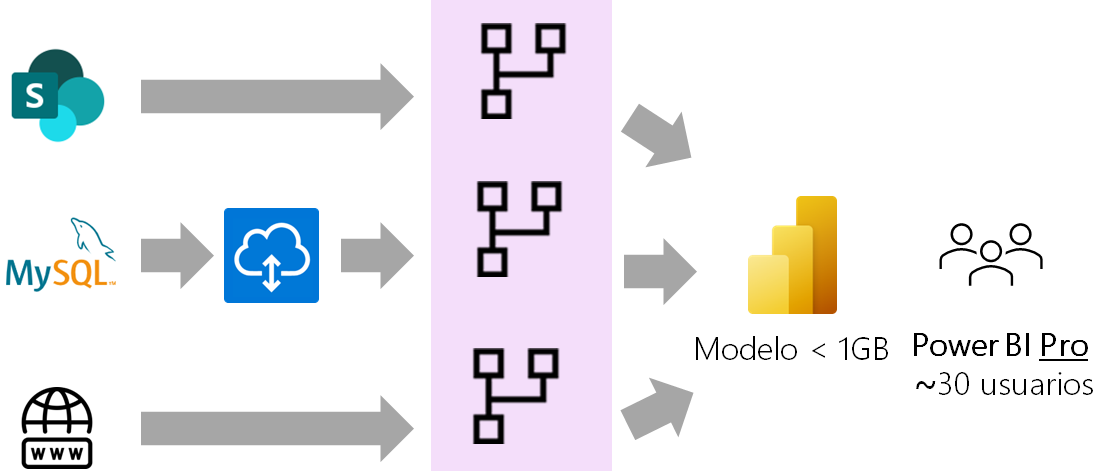
Como puedes ver en la imagen se utilizan distintos orígenes de datos y el proceso de ETL se realiza con flujos de datos GEN 1. El problema que tenemos es que este proceso es muy lento y no se puede realizar actualización incremental de los datos porque esa opción solo está disponible en las capacidades Premium y PPU.
El primer origen de datos es una carpeta de SharePoint donde están almacenados en ficheros CSV los datos de las entidades del negocio: clientes, productos, tiendas y vendedores.
También en SharePoint, dentro de la carpeta presupuestos, están almacenados en archivos CSV los presupuestos mensuales.
Y en la carpeta tickets están los tickets de soporte de los clientes almacenados en archivos CSV diarios.

El segundo origen de datos es MySQL. Este origen es on premise y requiere de una puerta de enlace para su actualización. Tienen dos bases de datos: Empresa EUR y Empresa USD. Ambas bases de datos contienen una tabla Ventas que tiene la misma estructura, una para almacenar las ventas en euros y otra para las ventas en dólares. Los datos de las dos tablas han de combinarse para analizar las ventas totales:

El último origen de datos es una API REST de donde se descarga cada día un archivo JSON con el cambio de la moneda. En el informe las ventas totales se muestran en euros por lo que es necesario transformar los valores costes y precios unitarios de la tabla Ventas de la base de datos Empresa USD de dólares a euros antes de combinarlas.
El proceso de ETL lo realizamos en flujos de datos GEN 1, en el servicio Power BI. Desde Power BI Desktop nos conectamos a los flujos de datos y cargamos los datos en el modelo. El archivo resultante pesa menos de 1 GB.
El proceso de ETL es muy lento y la idea es mejorarlo. Una de las opciones que hemos valorado es utilizar licencias PPU para cada usuario, que tienen un coste de 18,00 euros mensuales aproximadamente. Esto nos brinda una mejora significativa que es que podemos utilizar actualización incremental en los flujos de datos GEN 1 pero tiene la desventaja de que el coste de licencias se dispara alrededor de los 600 € mensuales.
Arquitectura propuesta
La otra idea que hemos tenido y que es por la que queremos apostar es utilizar la Capacidad Fabric y aprovechar todas las ventajas que nos ofrece. Utilizaríamos Fabric solo para realizar la ETL y luego se cargarían los datos en un modelo semántico que estaría en otra área de trabajo con capacidad Power BI en lugar de Fabric. Una vez cargados los datos en el modelo semántico, la capacidad Fabric se apagaría hasta la próxima actualización. El reto está en encender y apagar Fabric a nuestra conveniencia.
La arquitectura propuesta es la que se muestra en la siguiente imagen:
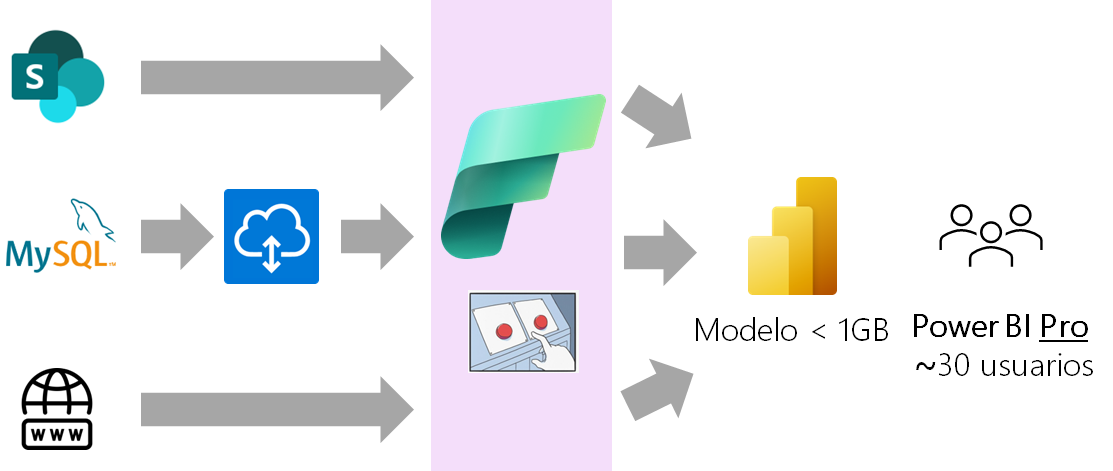
Para implementar esta arquitectura siguiendo las buenas prácticas de diseño recomendadas para Fabric y como continuación de la metodología de trabajo de buenas prácticas para organizar las consultas en el editor de Power Query, de la que ya hemos hablado en otras entradas de nuestro blog, hemos implementado la arquitectura medallion de almacén de lago.
Esta arquitectura es un patrón de diseño de datos que se utiliza para organizar lógicamente los datos en un lakehouse y consta de tres capas o zonas distintas, aunque pueden ser más. Cada capa tiene como objetivo mejorar de forma incremental y progresiva la estructura y la calidad de los datos almacenados en el lago a medida que fluyen a través de cada capa. Este enfoque multicapa nos ayuda a crear una única fuente de la verdad para los datos empresariales.
La siguiente imagen muestra la arquitectura medallion que hemos diseñado para nuestra prueba de concepto. Como se observa en la imagen se ha creado un Lakehouse para almacenar los datos de cada capa.
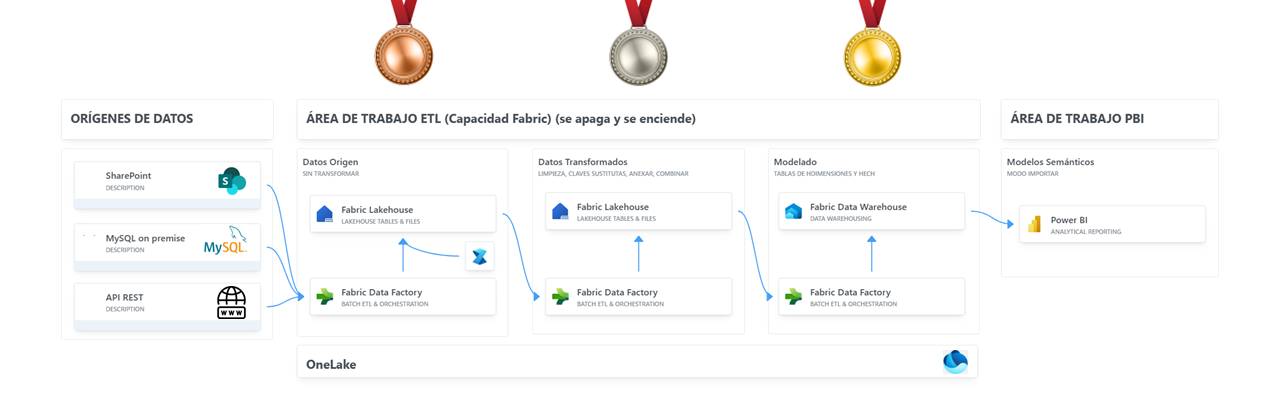
La primera capa, conocida como bronce y a la que llamamos datos_origen, almacena los datos tal y como están en el origen. La implementación típica requiere que los datos tengan la misma estructura y estén en el mismo formato que el origen.
La segunda capa, plata, es donde se realizan la mayor parte de las transformaciones sobre los datos. Al Lakehouse de esta capa le hemos llamado datos_transformados. Aquí se realiza la limpieza de los datos, se crean las claves sustitutas, se anexan y combinan tablas.
La última capa, oro, es donde se enriquecen los datos y se aplica la capa final de transformaciones de datos y reglas de calidad de datos para crear el esquema de estrella con sus tablas de hechos y dimensiones. A esta capa la hemos llamado modelo_datos. A esta capa nos conectaríamos desde Power BI para importar los datos al modelo semántico.
Para orquestar todo el proceso de ETL hemos creado una canalización que hemos llamado etl_completa.

Esta canalización a su vez llama a otras canalizaciones y componentes para realizar las tareas requeridas en cada capa y de las cuales hablaremos en próximas entradas.
2 comentarios
aguilarmercaderFeb 19, 2024 - 10:26 am
Impacientes por la próxima entrega. Muchas gracias a los dos por vuestro trabajo y esfuerzo.
Un abrazo desde Murcia.
Diana Aguilera ReynaFeb 19, 2024 - 4:09 pm
Hola José Carlos,
Muchas gracias por tu comentario. Esta semana sale el próximo.
Saludos,
Diana.