Continuando la serie, hoy hablaremos de la primera capa de la arquitectura Medallion que diseñamos para nuestra prueba de concepto en la primera entrada. A esta capa se conoce como Bronce y su característica fundamental es que los datos se almacenan tal y como están en el origen. La implementación típica requiere que los datos tengan la misma estructura y estén en el mismo formato que en el origen.
En nuestro caso de uso hemos llamado a esta capa Datos Origen y no sigue la implementación típica al pie de la letra, ya irás descubriendo por qué. Los datos los almacenaremos en un Lakehouse y para importarlos utilizaremos los componentes de ingeniería de datos de Fabric: los flujos de datos GEN 2, las canalizaciones y los cuadernos de notas de Spark.

Antes de continuar con la lectura sería bueno que revisaras la primera entrada de la serie donde hablamos de los orígenes de datos con los que trabajamos y que son del tipo: carpeta de SharePoint, bases de datos MySQL (On Premise) y API REST. También es bueno recordar que nuestro objetivo es mejorar el proceso de ETL de un modelo semántico que tenemos y que es un poco lento.
Comenzamos
Partimos de que tenemos un área de trabajo con capacidad Fabric donde realizaremos la ETL de los datos. Uno de los objetos que podemos crear en un área de trabajo con capacidad Fabric es un Lakehouse, para almacenar los datos en archivos y tablas. También podemos tener accesos directos a datos de otro Lakehouse dentro de nuestro OneLake o externos al OneLake como pudieran ser datos de Azure Data Lake GEN 2. Los accesos directos evitan tener copias de los datos en diferentes lugares.
Lakehouse
Lo primero que haremos será crear el Lakehouse que almacenará los datos de la capa bronce, al que llamaremos datos_origen.
Cuando creamos un Lakehouse se crean automáticamente un punto de conexión SQL, de solo lectura, que podemos utilizar para explorar los datos y un modelo semántico predeterminado. Si no vamos a utilizar el modelo semántico de esta capa podemos desactivar la sincronización. En la siguiente imagen podemos ver el Lakehouse datos_origen con el punto de conexión SQL y el modelo semántico predeterminado.
Copia de datos
Una vez que hemos creado el destino de los datos comenzamos el proceso de carga.
Carpeta de SharePoint
Los primeros datos que «aterrizaremos» en el Lakehouse son los de SharePoint.
En SharePoint todos los datos están en formato CSV, en una carpeta llamada Datos que contiene:
- 5 archivos: clientes, tiendas, productos, vendedores y municipios
- y dos subcarpetas: presupuestos y tickets
El volumen de datos de presupuestos y tickets es alto. En el caso de los presupuestos se genera un archivo mensual y en el caso de los tickets un archivo diario. Es por esta razón que implementaremos la actualización incremental para estos orígenes de datos.
Lo ideal para copiar datos de los orígenes al Lakehouse es utilizar una actividad de copia de una canalización. La copia es muy rápida y permite guardar los datos en archivos igual que como están en el origen pero nos encontramos con una dificultad y es que las canalizaciones no admiten, de momento, como orígenes de datos archivos de SharePoint. En este artículo hemos visto que se puede llegar a implementar pero es un poco complicado y tendríamos que utilizar componentes externos a Fabric.
Decidimos entonces utilizar los flujos de datos GEN 2 para importar los datos de SharePoint y creamos un flujo al que llamamos copiar_datos_sharepoint.
Flujos de datos GEN 2
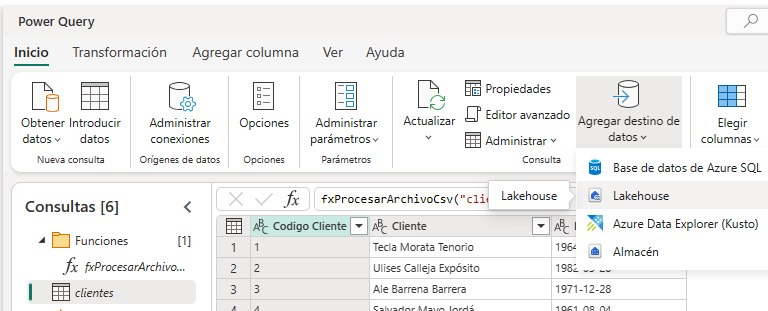
Los flujos de datos GEN 2 tienen ventajas sobre los flujos de datos GEN 1, la más importante es que separan el almacenamiento de los datos del motor de procesamiento. Las consultas que se crean utilizando los flujos de datos GEN 2 pueden tener destinos diferentes e incluso no tener destino. En la siguiente imagen se muestran los destinos disponibles hasta la fecha para los flujos de datos GEN 2: Base de datos Azure SQL, Lakehouse, Azure Data Explorer (Kusto) y Almacén (Warehouse).
Los flujos de datos internamente utilizan un almacenamiento provisional para los datos, un Lakehouse, donde se preparan los datos que se ingieren, y un Warehouse, utilizado como motor de cálculo y medio para escribir los resultados en los destinos de salida admitidos. La siguiente imagen muestra los componentes del flujo de datos y fue tomada de la entrada Data Factory Spotlight: Dataflow Gen2 de Miguel Escobar en el blog de Fabric donde podrás encontrar más información acerca del tema.

Cuando no se va a utilizar la computación del Warehouse, o cuando la preparación provisional está deshabilitada para una consulta, el motor de mashup extraerá, transformará o cargará los datos en la preparación provisional o en el destino. A cada consulta se le puede deshabilitar el staging y es lo recomendado en el caso de que se vayan a almacenar los datos en un destino y no necesite realizar grandes procesamientos de datos.
Para deshabilitar el almacenamiento provisional de una consulta la seleccionamos y en el menú contextual podemos habilitar o deshabilitar la opción como se muestra en la siguiente imagen.

Los flujos de datos tienen una dificultad para su uso en esta capa y es que el destino Lakehouse almacena los datos en tablas en lugar de archivos por lo que no sería exactamente igual que el origen. Para compensar esta dificultad decidimos que las columnas de cada tabla serían de tipo texto y de esta forma mantener los datos lo más parecido a como estaban en el origen.
En el caso de los 5 archivos, se creó una consulta para cada uno tal y como estaban en el archivo original y se les asignó a todas las columnas el tipo texto de esta forma tratamos de garantizar que fueran lo más fiel al original.
En el caso de las carpetas presupuestos y tickets se crearon dos consultas presupuestos y tickets_soporte. A cada consulta se le añadieron 2 columnas: archivo_origen con el nombre del archivo original y fecha_actualizacion con la fecha y hora de actualización. La columna archivo_origen se utilizará para configurar la actualización incremental. La columna fecha_actualizacion servirá para mantener el registro histórico de los datos, utilizando esta columna podremos ver el estado de los datos en un momento concreto.
En esta capa no necesitamos realizar transformaciones sobre los datos por lo que deshabilitaremos el almacenamiento provisional a cada consulta.
La siguiente imagen muestra el flujo de datos copiar_datos_sharepoint donde se pueden ver todas las consultas creadas a partir de SharePoint. En la imagen está seleccionada la consulta tickets_soporte y podemos observar que todas las columnas son de tipo texto. También podemos ver las columnas añadidas archivo_origen y fecha_actualizacion que no estaban en los archivos de origen y que hemos añadido en el proceso de extracción. La columna fecha_actualizacion es la única que no es de tipo texto.
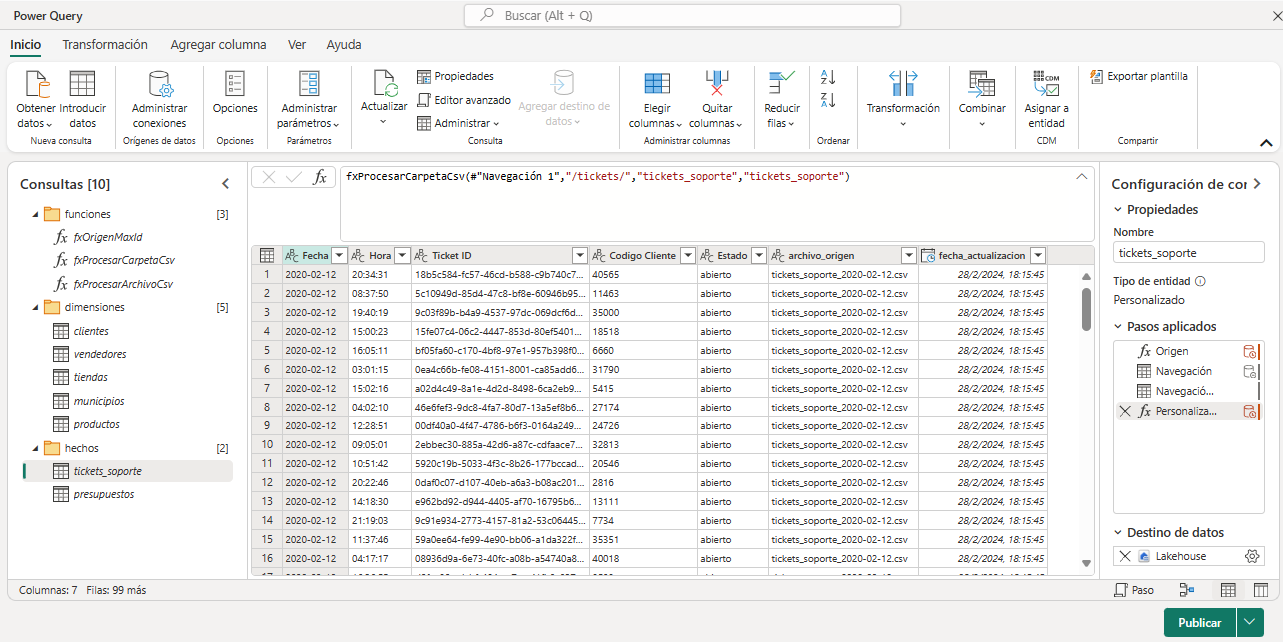
Para cada consulta que necesitamos cargar en el Lakehouse debemos configurar su destino. En la imagen se muestra el destino de la consulta tickets_soporte, en la parte inferior derecha, se puede observar que el destino seleccionado es Lakehouse.
Base de datos MySQL
En el caso del origen MySQL, como son 2 bases de datos en un servidor On Premise, necesitamos utilizar una puerta de enlace para conectarnos a los datos. Por este motivo no podemos utilizar una actividad de copia de una canalización para importar los datos que hubiera sido lo ideal. Las canalizaciones, en el momento de escribir el artículo, todavía no soportan las puertas de enlace y es por esto que también utilizamos un flujo de datos GEN 2 para importar los datos, al que llamamos copia_datos_mysql.
El flujo de datos contiene dos consultas una por cada base de datos. La estructura de los datos es la misma en las dos consultas, solo cambia la moneda en la que se almacenan los datos.
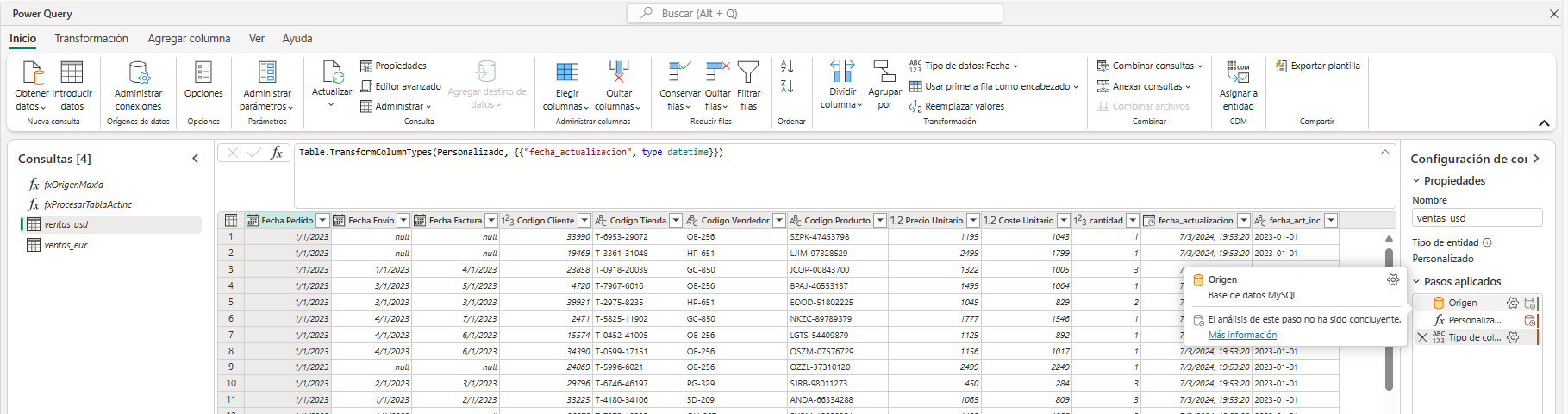
Al igual que en el caso de las consultas presupuestos y tickets_soporte añadimos 2 columnas, fecha_actualizacion con la fecha y hora de actualización y fecha_act_inc de tipo texto con la fecha de actualización solamente. Estas columnas se utilizarán igual que en el caso anterior, la primera para mantener un histórico de los datos y la segunda para implementar la actualización incremental.
Configurar destino de las consultas
Una vez que terminamos de transformar los datos debemos especificar el destino de las consultas. Como ya hemos dicho utilizaremos las tablas del Lakehouse.
Cuando seleccionamos el destino Lakehouse se muestra un asistente que nos ayudará a configurarlo. Lo primero es seleccionar la conexión al Lakehouse.
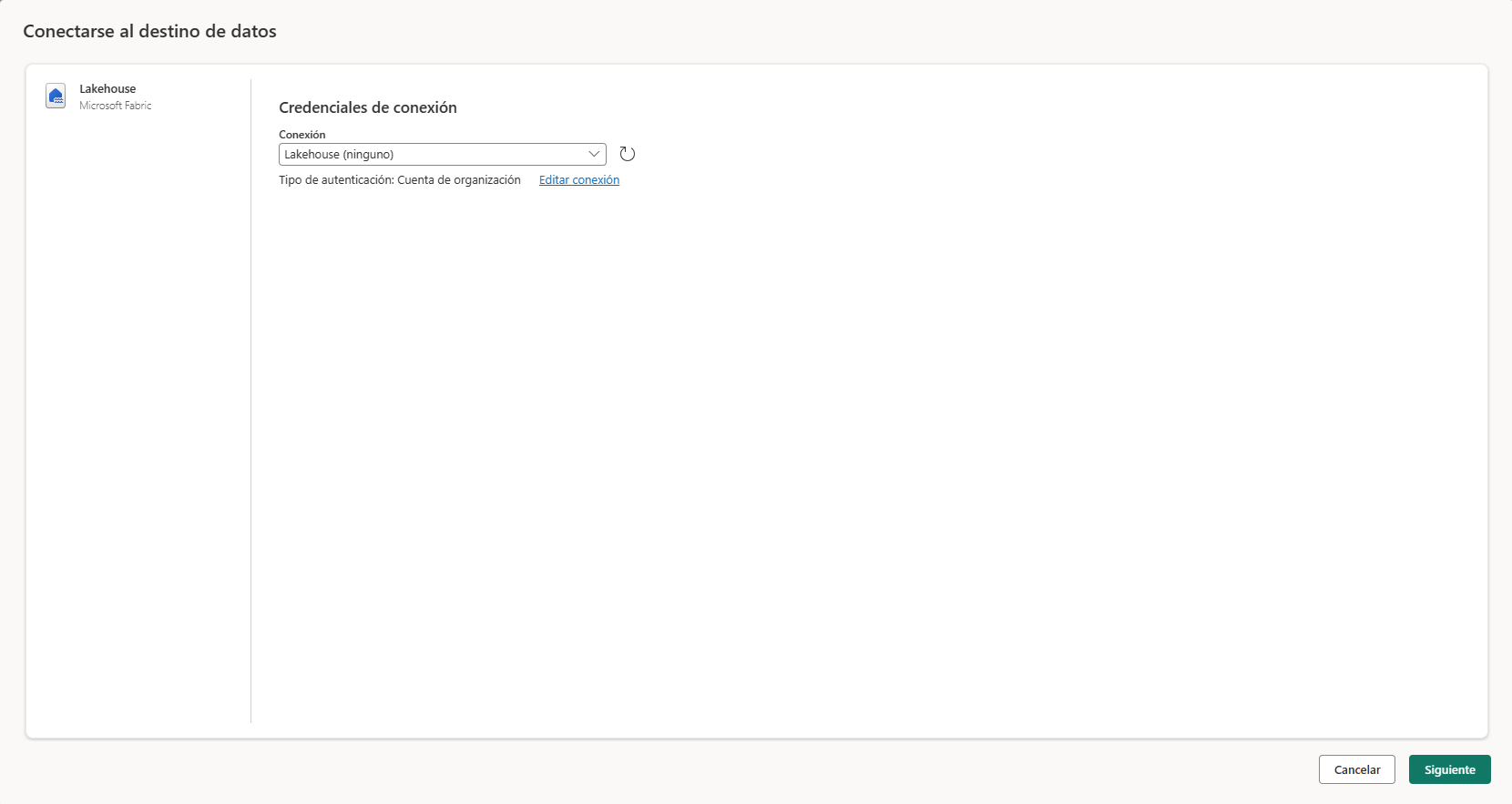
A continuación, seleccionamos el área de trabajo y el Lakehouse donde se almacenará la tabla. Debemos especificar si la tabla es nueva o ya existe y el nombre.
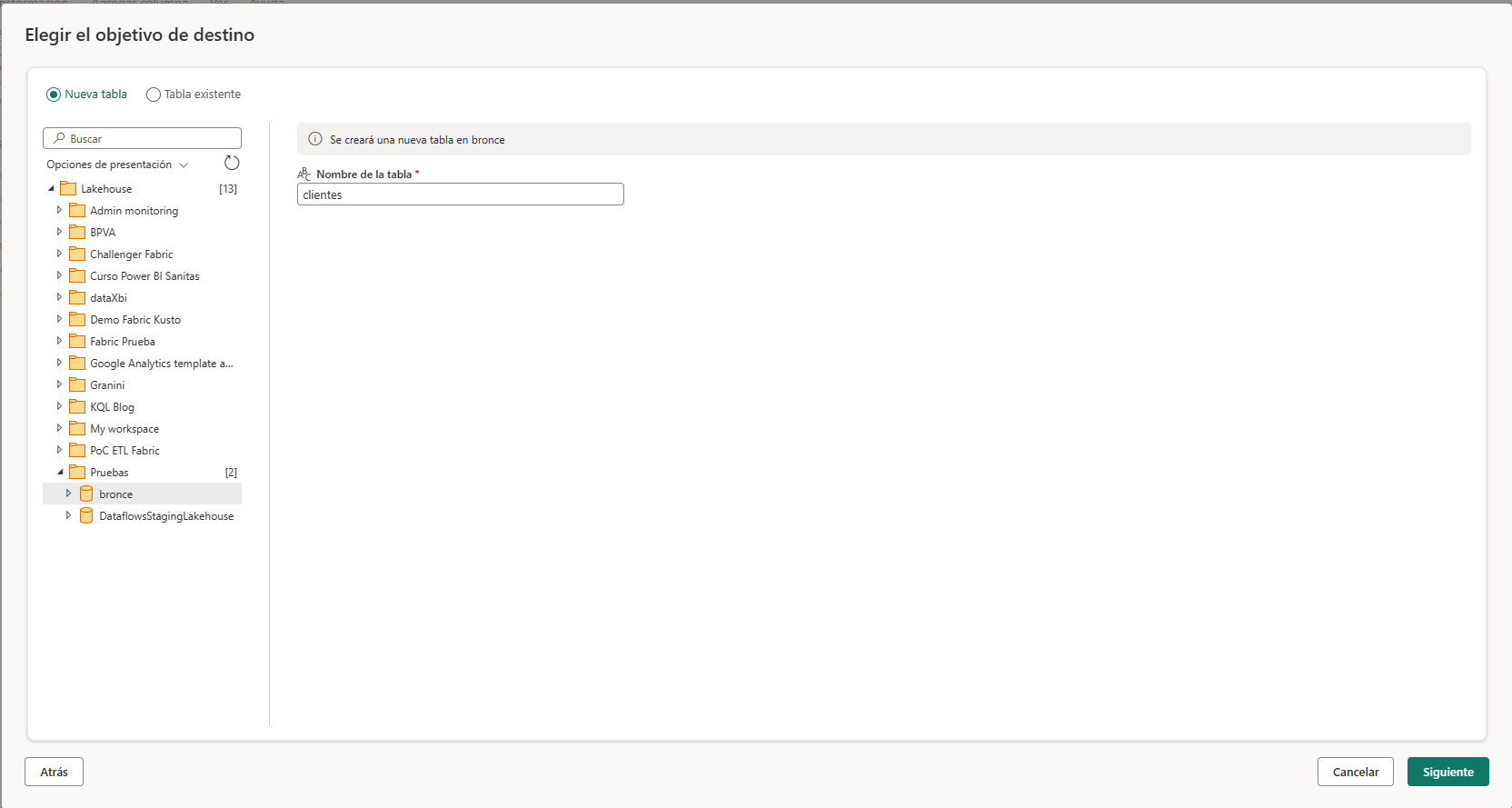
A continuación configuramos el método de actualización de la tabla destino de los datos. Debemos elegir si queremos reemplazar o anexar los datos en la tabla. En nuestro caso de uso las tablas clientes, tiendas, productos y vendedores reemplazarán los datos de la tabla por los nuevos valores, no hemos considerado mantener un histórico de los datos y tampoco creemos que es necesario una actualización incremental de los mismos porque su volumen no es alto. En el caso de las tablas presupuestos, tickets_soporte, ventas_usd y ventas_eur hemos utilizado la opción Anexar porque configuraremos actualización incremental al ser alto el volumen de datos de esta forma la actualización de los datos consumirá menos tiempo.
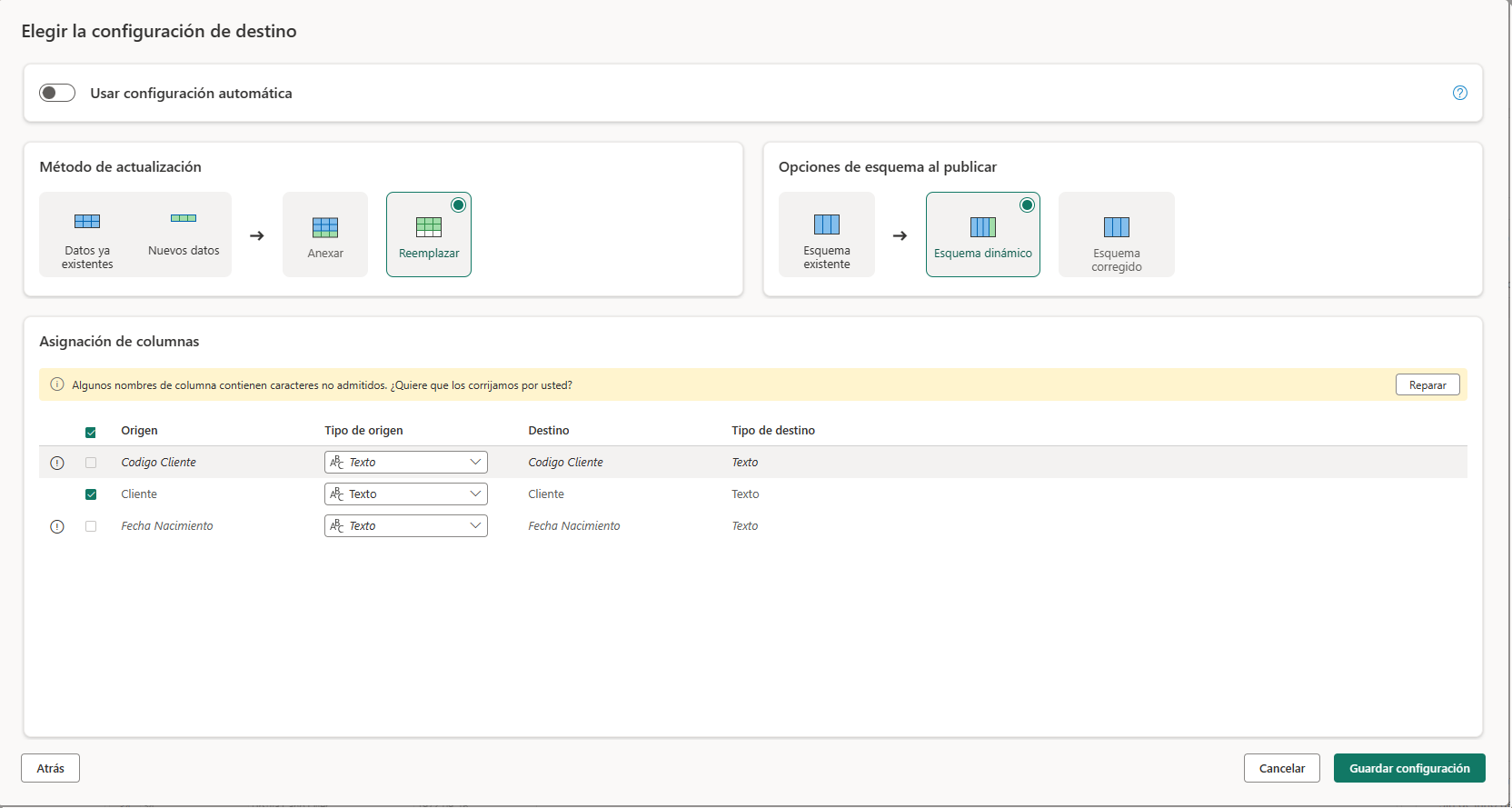
También debemos configurar la asignación de columnas del destino. Debemos mapear los nombres de las columnas y el tipo de datos correspondiente. Los nombres de las columnas no deben contener espacios en blanco. En el caso de que los nombres del origen contengan espacios nos muestra el error como se ve en la imagen anterior y nos propone corregirlo automáticamente. Lo que hará será reemplazar los espacios por el caracter subrayado o guion bajo «_».
Las opciones de esquema al publicar solo se aplican cuando el método de actualización sea reemplazar. Al anexar datos, no es posible realizar cambios en el esquema.
Elegir un esquema dinámico, permite realizar cambios de esquema en el destino de los datos cuando se vuelva a publicar el flujo de datos. Debido a que no está utilizando la asignación administrada, aún debe actualizar la asignación de columnas en el flujo de destino del flujo de datos cuando realice cambios en su consulta. Cuando se actualice el flujo de datos, su tabla se eliminará y se volverá a crear. La actualización del flujo de datos fallará si agrega alguna relación o medida a su tabla.
Al elegir un esquema fijo, no es posible realizar cambios en el esquema. Cuando se actualiza el flujo de datos, solo las filas de la tabla se eliminarán y se reemplazarán con los datos de salida del flujo de datos. Cualquier relación o medida sobre la tabla permanecerá intacta. Si realiza algún cambio en su consulta en el flujo de datos, la publicación del flujo de datos fallará si detecta que el esquema de la consulta no coincide con el esquema de destino de los datos. Utilice esta configuración cuando no planee cambiar el esquema y agregar relaciones o medidas a su tabla de destino. Al cargar datos en un Warehouse, solo se admite el esquema fijo.
Puedes ampliar la información de los destinos que admiten un esquema dinámico en el blog de Microsoft Fabric.
API REST
El último origen es la API REST de donde necesitamos descargar cada día un archivo JSON con la tasa de cambio de ese día. La idea es almacenar en una carpeta los archivos JSON en lugar de sobrescribirlos y para eso hemos añadido un sufijo al nombre del archivo con la fecha de descarga. Para este origen si pudimos utilizar una canalización con una actividad de copia a la que llamamos descargar_conversion_divisas y que puedes ver en la siguiente imagen.

En la canalización hemos definido las propiedades necesarias para la actividad de copia: Origen y Destino. En el origen hemos especificado la conexión a la API REST y en destino hemos elegido como Lakehouse de destino datos_origen, el de nuestra capa de bronce. Los datos se almacenarán en archivos para mantener el formato de origen y esto se especifica en la propiedad Carpeta raiz. El nombre de la carpeta es la primera parte de la ruta de acceso al archivo y se le llamó conversion_divisas. La segunda parte de la ruta es el nombre del archivo, en este caso conversion_eur_. Al nombre del archivo se le ha añadido un sufijo con la fecha de actualización para no sobrescribir el del día anterior. Por último se especificó el formato del archivo, en este caso JSON.

La canalización ya está lista, no requiere ninguna otra configuración.
Desactivar la sincronización del modelo semántico predeterminado
El modelo semántico predeterminado de este Lakehouse no lo vamos a necesitar y podemos deshabilitar la sincronización desde el punto de conexión SQL.
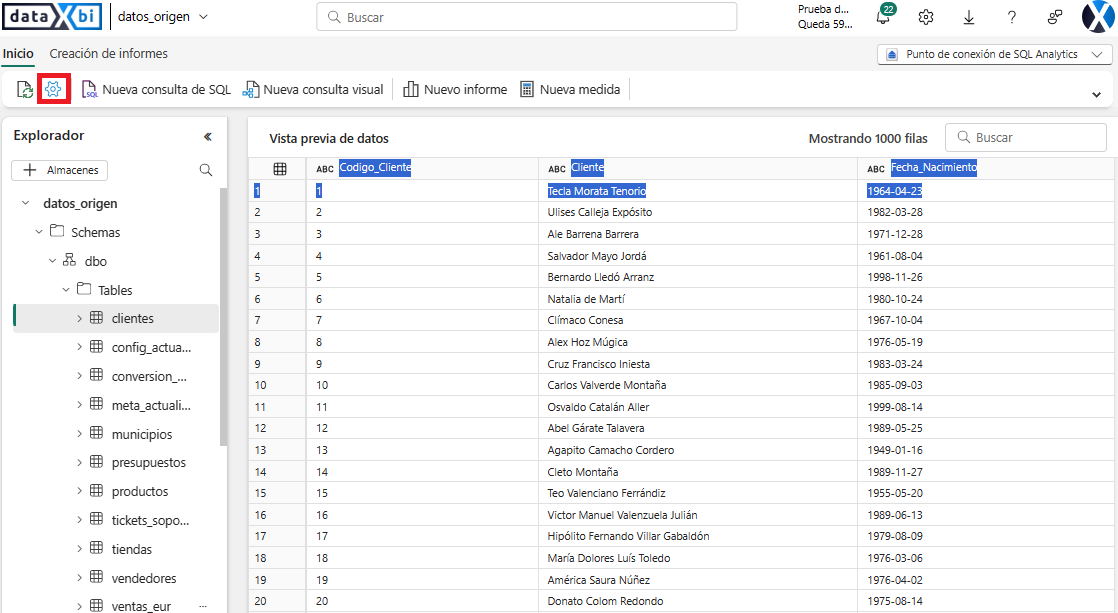
Desde el punto de conexión de SQL seleccionamos la opción Configuración del menú y a continuación la opción Modelo semántico de Power BI predeterminado y aquí deshabilitamos la sincronización del modelo semántico.

Orquestar el proceso completo de carga de datos
Ya tenemos implementados los procesos de carga para cada uno de los orígenes de datos ahora necesitamos organizar en que orden se ejecutará cada proceso y que debemos hacer en caso de que falle alguno. La mejor opción para ello es crear una canalización que orqueste todo el proceso de carga y es lo que hemos hecho, una canalización a la que hemos llamado copiar_datos_origen y de la cuál puedes ver una imagen.

Esta canalización se encarga de coordinar todos los procesos de ETL en el orden en que aparecen. En la imagen puedes ver que además de los flujos de datos copiar_datos_sharepoint y copiar_datos_mysql y la canalización descargar_conversion_divisas hay un flujo de datos Copiar Datos Config y un cuaderno de notas Registrar Actualización. Estas dos actividades se utilizan para implementar la actualización incremental que será el contenido de la próxima entrada del blog.
Una vez ejecutada la canalización copiar_datos_origen podemos ver las tablas y archivos creados en el Lakehouse como se muestra en la siguiente imagen.
Además de las tablas y archivos que se crearon a partir de cada origen de datos hay otras dos config_actualizacion_in y meta_actualizacion_inc que se han creado y utilizado en la actualización incremental de las tablas presupuestos, tickets_soporte, ventas_eur y ventas_usd.
En la próxima entrada te mostraremos cómo se implementó la actualización de las tablas a pesar de que los flujos de datos GEN 2 no tiene esta característica que si la tienen los flujos GEN 1 y que es una desventaja respecto a estos.