En esta nueva entrega de nuestra serie sobre ETL low cost con Microsoft Fabric hablaremos de cómo hemos implementado una carga incremental desde algunos orígenes de datos hacia la capa bronce, utilizando los Flujos de Datos Gen2.
La carga incremental la vamos a hacer para los siguientes orígenes:
-
Bases de datos MySQL:
Hay dos bases de datos separadas, aunque con la misma estructura, una para las ventas en euros y otra para las ventas en dólares. La tabla
ventasde cada base de datos contiene un registro de cada artículo que se ha vendido y usaremos la columnaFecha Pedidopara cargar hacia la capa bronce las últimas ventas desde la última carga. -
Carpeta Sharepoint con los presupuestos: En esta carpeta hay archivos CSV con los presupuesto para cada tienda por año y mes. Cada archivo contiene los datos de un mes y su nombre sigue un formato como este:
presupuesto_2020_01.csv, correspondiente al mes de enero de 2020, y usaremos dicho nombre para filtrar los archivos que falten por copiar hacia la capa bronce desde la última carga. -
Carpeta Sharepoint con tickets de soporte: En esta otra carpeta hay archivos CSV con un registro de los tickets de soporte a los clientes. Cada archivo contiene los tickets de un día y su nombre sigue un formato como este:
tickets_soporte_2020-01-01.csvque corresponde al 1 de enero de 2020, y también usaremos dicho nombre para filtrar los archivos que falten por copiar hacia la capa bronce desde la última carga.
Resumiendo lo anterior, para filtrar los datos a cargar, en unos casos se utilizará una columna de tipo fecha de una tabla de una base de datos, y en otros casos se utilizará una parte del nombre de los archivos de una carpeta.
La razón por la que hemos utilizado los Flujos de Datos Gen2 para cargar estos datos a la capa bronce ya la explicamos en una entrada anterior de esta serie, y en esencia es porque por el momento las canalizaciones de Fabric no soportan de manera nativa la conexión a carpetas de Sharepoint o a orígenes que requieran una puerta de enlace.
Y una limitante que tienen por el momento los Flujos de Datos Gen2 es precisamente que no implementan la actualización incremental, como si se puede hacer con los Flujos de Datos Gen1 siempre que residan en un área de trabajo con capacidad Premium.
Pero afortunadamente, no todo está perdido y es posible implementar una carga incremental utilizando una combinación de las nuevas funcionalidades ofrecidas por los Flujos de Datos Gen2 y por otros componentes de Fabric. Y de hecho hay algunas soluciones creadas por miembros de la comunidad y como no nos gusta inventar la rueda, hemos partido de la solución propuesta por Patrick LeBlanc, de Guy in a Cube, en este vídeo y que a su vez está inspirada en un artículo de Alex Powers.

La principal diferencia que tiene nuestra solución con la de Patrick es que mientras él utiliza un Datawarehouse de Fabric, nosotros utilizamos un Lakehouse, y esto tiene la consecuencia de que tendremos que usar un bloc de notas de Spark donde él utiliza un procedimiento almacenado.
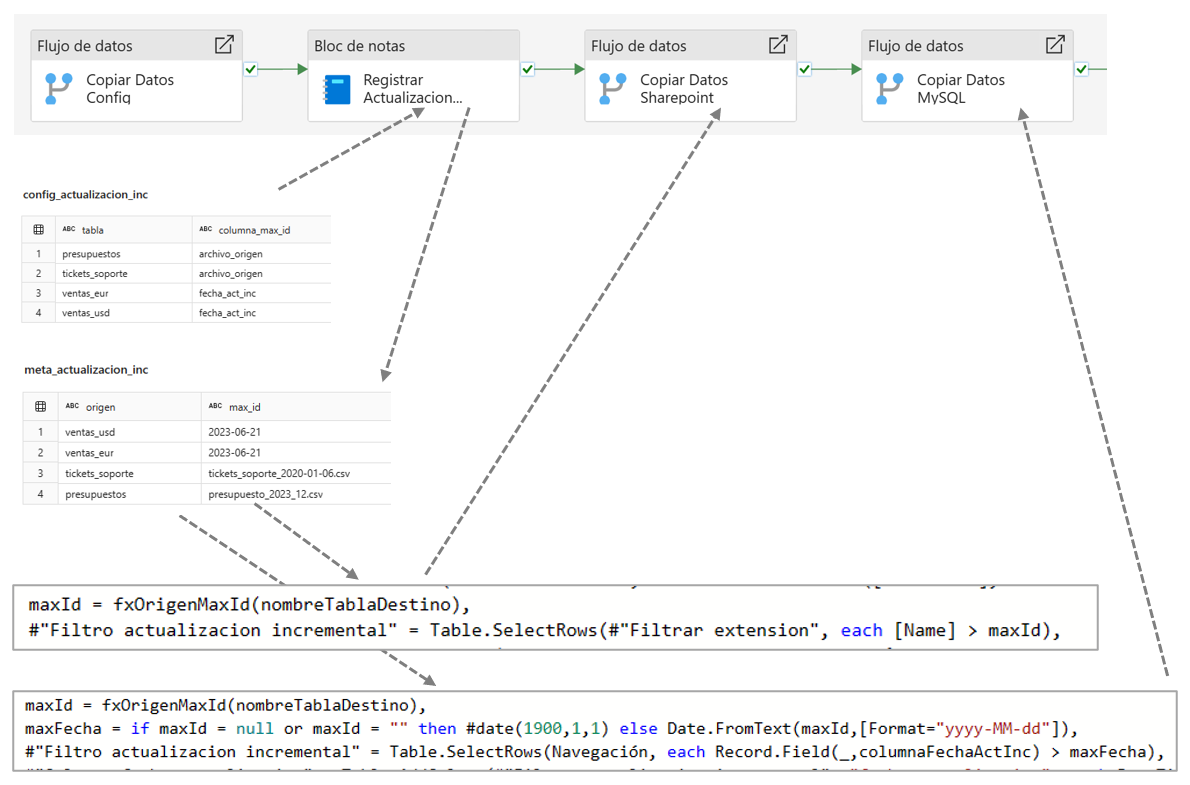
Estos son los componentes de nuestra solución:
- El lakehouse donde están los datos de la capa bronce.
- Un archivo CSV para saber qué tablas tendrán actualización incremental y cuál será la columna que se utilizará para filtrar los datos. Este archivo tiene el nombre config_actualizacion_inc.csv y tiene dos columnas con los nombres tabla y columna_max_id, y se carga mediante un flujo de datos gen2 a una tabla del lakehouse con el nombre
config_actualizacion_inc. - Otra tabla en el lakehouse con el nombre
meta_actualización_incy que guarda por cada tabla con actualización incremental el valor máximo de la columna de filtrado. Esta tabla tiene dos columnas con los nombres origen y max_id. - Un bloc de notas Spark que recorre las tablas indicadas en
config_actualizacion_incpara averiguar el valor máximo de cada columna y actualizar la tablameta_actualización_inc. - Una función en Power Query M que hemos creado con el nombre
fxOrigenMaxIda la que se le pasa como parámetro el nombre de una tabla y devuelve el valor máximo de la columna, según lo almacenado en la tablaconfig_actualizacion_inc. Esta función se utiliza en las consultas donde se va a utilizar la actualización incremental para obtener el valor con el que se van a filtrar las filas. - Una canalización que orquesta todo el proceso: 1) ejecuta el flujo que carga en archivo CSV en la tabla
config_actualizacion_inc2) ejecuta el bloc de notas que actualiza la tablameta_actualización_inc3) ejecuta los flujos de datos que cargan las tablas con actualización incremental y que utilizan la funciónfxOrigenMaxId.
En el siguiente diagrama intento representar el proceso, mostrando la canalización, las tablas de configuración y una muestra de dos consultas Power Query M donde se filtran los datos utilizando la función fxOrigenMaxId, en el primer caso para una columna de tipo texto correspondiente al nombre de un archivo, y en el segundo caso correspondiente al filtrado de una columna de tipo fecha.
Para completar la configuración, en las consultas que utilicen la actualización incremental, al seleccionar el destino de los datos hay que indicar que utilice el método de actualización Anexar, como se muestra en la siguiente imagen.

Me parece importante señalar que para que este método funcione bien es necesario ejecutar la canalización completa y evitar ejecutar los flujos de datos con actualización incremental de manera independiente.
Para terminar dejo por aquí dos imágenes con el código del bloc de notas Spark y de la función Power Query M.

