En febrero de 2024 comenzamos la serie de blogs PoC ETL low cost con Fabric, donde propusimos una implementación de la arquitectura medallion con la idea de mejorar el proceso de ETL de un cliente sustituyendo los flujos de datos Gen1 por los componentes de ingeniería de datos de Fabric: flujos de datos Gen2, canalizaciones y cuadernos de notas Spark.
A partir de un año de experiencias en eventos, formaciones y proyectos, queremos proponerte una serie de mejoras respecto a esa primera versión que logren disminuir los costes de Fabric y hagan más eficientes los procesos que se llevan a cabo.
Eso sí, manteniendo nuestra idea original de realizar el ETL o ELT en un área de trabajo con capacidad Fabric y tener el modelo semántico en otra área de trabajo con capacidad PRO y la posibilidad de apagar y encender la capacidad Fabric para realizar la ETL y cargar los datos en el modelo semántico.
Este es el primer blog de una nueva serie donde te iremos mostrando en detalle como implementar los cambios y mejoras que te proponemos en esta entrada.
Arquitectura actual
En la siguiente imagen se muestra la arquitectura resultante de nuestra propuesta anterior:

En esta arquitectura tenemos tres capas: Bronce, Plata y Oro. La capa Broce almacena los datos sin transformar, la capa Plata los datos limpios y la capa Oro los datos modelados. Para el almacenamiento de los datos en las capas Bronce y Plata utilizamos un Lakehouse mientras que en la Oro utilizamos un Warehouse (Almacén). Los flujos de datos Gen2 se utilizaron tanto para la carga de los datos como para las transformaciones. Las canalizaciones se utilizaron para la extracción de datos de uno de los orígenes (API REST) y para orquestar todo el proceso de ETL, en cada capa y de manera general.
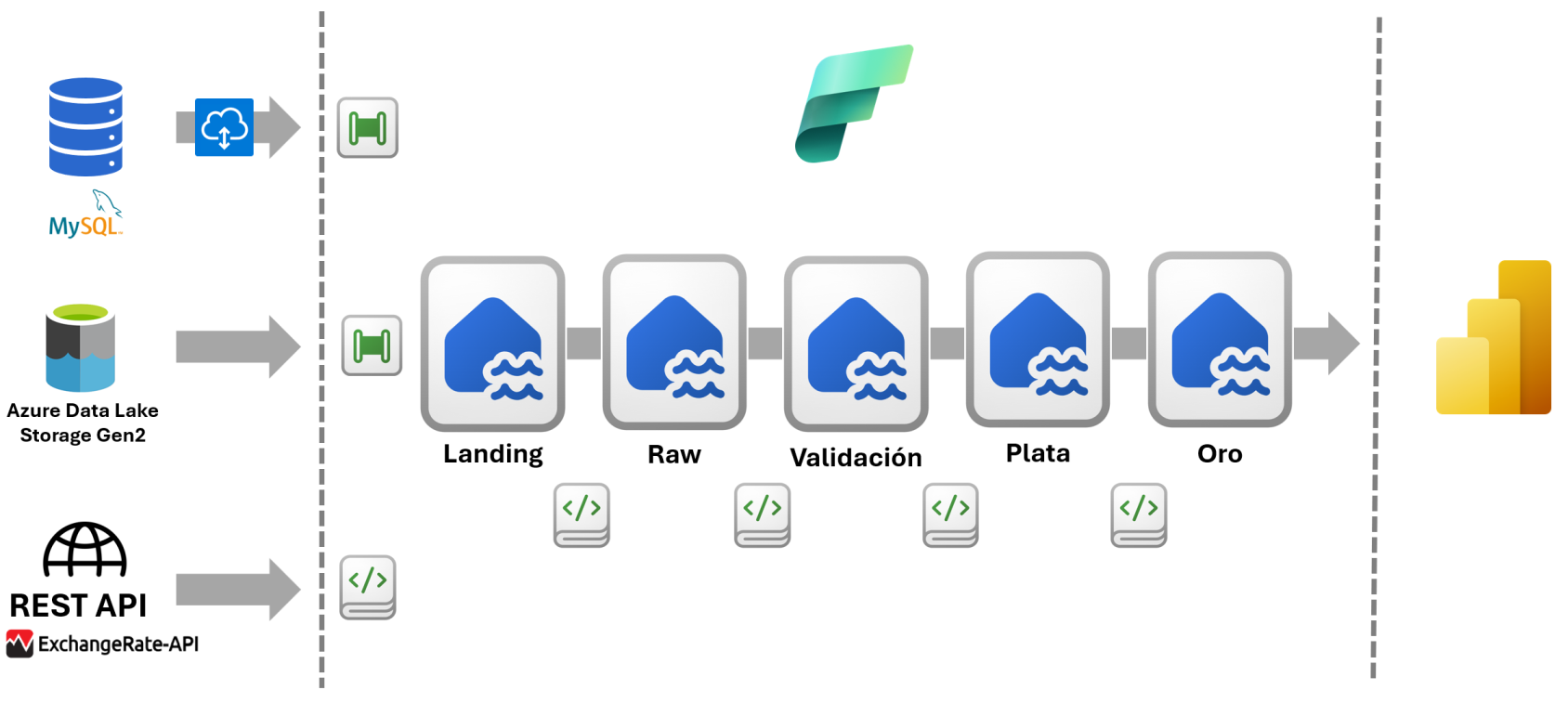
Arquitectura propuesta
La arquitectura propuesta sigue siendo una arquitectura medallion pero tiene una serie de diferencias y mejoras respecto a la anterior que son:
- Sustituiremos el origen de datos SharePoint por Azure Data Lake Storage Gen2.
- Separamos la capa Bronce en tres capas y se mantienen las capas Plata y Oro tal y como están ahora.
- No utilizaremos los flujos de datos Gen2. En su lugar utilizaremos cuadernos de notas Spark y canalizaciones.
- Para realizar la extracción de los datos utilizaremos por defecto las canalizaciones de datos y en algunos casos concretos los cuadernos Spark.
- En la transformación y el modelado de los datos utilizaremos los cuadernos Spark.
- Para orquestar todo el proceso de ETL utilizaremos las canalizaciones de datos.
Para tomar la decisión de sustituir SharePoint por ADLS Gen2 tuvimos en cuenta que desde SharePoint no podíamos utilizar las canalizaciones de datos para la extracción de datos, al menos de una forma sencilla y utilizando solo Fabric. Las canalizaciones de datos son la opción recomendada por Microsoft para esta tarea porque proporcionan una manera de mover datos del origen al destino de forma confiable, escalable y eficaz. También tuvimos en cuenta que el coste de almacenamiento de los datos en ADLS Gen2 es muy económico.
Capa Bronce: Dividir en Landing, Raw y Validación
En lugar de tener una sola capa, Bronce, la propuesta es tener tres capas: Landing, Raw y Validación. Cada capa tendrá su propio Lakehouse y funcionalidades diferentes. La capa Bronce de la versión anterior es equivalente a la capa Raw de la nueva propuesta. En la versión anterior los datos se almacenaban en tablas y no se validaban.
Capa Landing
La primera capa, Landing, almacenará una copia de los datos lo más exacta posible a como se encuentran en los orígenes de datos con la finalidad de que sean la única fuente de la verdad y garantizar su inmutabilidad y trazabilidad. Los datos se anexan de manera incremental y aumentan con el tiempo. Permite volver a procesar y auditar conservando todos los datos históricos. No está pensada para el uso de analistas ni científicos de datos sino para de realizar cargas en la siguiente capa.
En esta capa los datos se almacenarán en archivos Parquet y JSON, dependiendo del origen.
Capa Raw
La segunda capa, Raw, almacenará los datos de la capa Landing en tablas Delta. Las tablas Delta almacenan los datos en formato columnar lo que nos proporciona mayores opciones para la compresión de los datos y nos permite realizar consultas más eficientes de un subconjunto de datos.
Solo se realizarán transformaciones mínimas sobre los datos con el fin de garantizar que cumplan con las restricciones de las tablas Deltas en Fabric. Los datos se almacenarán particionados, con estructura jerárquica de año, mes, día. Para cargar los datos se utilizarán cuadernos Spark parametrizados lo que permitirá la reutilización de los mismos.
Capa Validación
La tercera capa, Validación, comprobará que los datos almacenados en la capa Raw cumplan una serie de reglas predefinidas de antemano, esto nos permitirá garantizar la integridad y calidad de los datos que pasen a la capa Plata. Por cada tabla validada se crearán dos nuevas tablas en la capa Validación, una con las filas que contienen valores correctos para todas las columnas y otra con las filas que contienen errores en alguna de las columnas.
Entre las reglas que podemos validar están el que una columna no contenga valores vacíos, que el tipo de dato de la columna sea el esperado, que una columna contenga valores únicos, que los valores de una columna se encuentren dentro de un rango, que los valores de una columna estén dentro de una lista, etc.
Capa Plata
Esta capa se mantiene con un solo Lakehouse al que hemos llamado Plata y es donde se realizarán la mayor parte de las transformaciones sobre los datos. La novedad en esta propuesta es que esas transformaciones se llevarán a cabo con cuadernos de Sparks en lugar de flujos de datos Gen2. Con los cuadernos Spark tenemos que escribir código pero tiene la ventaja de que nos ofrece mayores opciones de parametrización y reusabilidad. Utilizaremos Data Wrangler y Copilot para que nos ayuden a escribir el código de algunas transformaciones.
La primera transformación que se llevará a cabo es la deduplicación de los datos y luego el resto de transformaciones como seleccionar columnas, recortar columnas de texto, convertir a mayúsculas el valor de algunas columnas de texto, etc.
Capa Oro
En esta capa es donde se realiza el enriquecimiento y modelado de los datos. Para el almacenamiento de los datos en lugar de proponerte un Almacén, como hicimos en la versión anterior, te proponemos 3 variantes dependiendo de tus requerimientos: Lakehouse, Almacén o SQL Database. Este último almacenamiento no existía cuando escribimos la serie anterior.
Para nosotros la opción recomendada es el Lakehouse pero depende del volumen de tus datos y del procesamiento que requieran. En el artículo ¿Qué es la arquitectura de medallón de Lakehouse? encontrarás un ejemplo de implementación de esta arquitectura.
La siguiente imagen muestra la nueva arquitectura propuesta.
Conclusiones
Esta nueva versión de la arquitectura resuelve problemas como la deduplicación y la validación de los datos que no se tuvieron en cuenta en la primera, además de dar varias opciones de almacenamiento de la capa Oro donde realizamos el modelado de los datos.
En nuevas entradas entraremos en los detalles de como implementar cada capa y acerca de las distintas capacidades de Fabric y sus costes.